Overview
This article illustrates several key points while applying the CNN with the LSTM in Computer Vision.Introduction
Nowadays, the Convolutional Neural Network (CNN) shows its great successes in many computer vision tasks, such as the image classification, the object detection, and the object segmentation... etc. However, most of these algorithms are only be able to apply on the image (or, the single frame). For example, most of the object detectors can detect and highlight the car which drives along the road. Since the object detector is designed to detect the car in a single frame (i.e. it cannot take temporal information into consideration), the object detector may fail to detect the car while it is currently occluded by a tree. However, we can still expect the position of the car because the human brain takes the history of the interested object into consideration.To overcome such issue, it's very intuitive to combine the CNN and the LSTM. However, there are several tricks to be noted when applying the LSTM in computer vision.
Notes:
1. Adding dropout and regularization
The LSTM is as easy as the fully-connected layer to get overfitting, not to mention that the LSTM can be seen as the 4 layers combination of the fully-connected layer.Fortunately, the TensorFlow provides the dropout wrapper for LSTM that can perform the dropout between the stacked LSTM (Note: this paper states that it'd be better to use dropout between the LSTM cells than use inside the cell.). See this website for more detail.
For the regularization, you need to get all of the variables first, then filter the variables of LSTM out by the name scope. See this website for more detail.
Finally, the wrapper function of LSTM is defined as follows:
def LSTM(name_, inputTensor_, numberOfOutputs_, isTraining_, dropoutProb_=None):
with tf.name_scope(name_):
cell = tf.nn.rnn_cell.LSTMCell(num_units=numberOfOutputs_,
use_peepholes=True,
initializer=layerSettings.LSTM_INITIALIZER,
forget_bias=1.0,
state_is_tuple=True,
activation=tf.nn.tanh,
name=name_+"_cell")
if dropoutProb_ != None:
dropoutProbTensor = tf.cond(isTraining_, lambda: dropoutProb_, lambda: 1.0)
cell = tf.nn.rnn_cell.DropoutWrapper(cell,
input_keep_prob=dropoutProbTensor,
output_keep_prob=dropoutProbTensor)
statePlaceHolder = tf.nn.rnn_cell.LSTMStateTuple( tf.placeholder(layerSettings.FLOAT_TYPE, [None, numberOfOutputs_]),
tf.placeholder(layerSettings.FLOAT_TYPE, [None, numberOfOutputs_]) )
outputTensor, stateTensor = tf.nn.dynamic_rnn( cell=cell,
initial_state=statePlaceHolder,
inputs=inputTensor_)
# Add Regularization Loss
for eachVariable in tf.trainable_variables():
if name_ in eachVariable.name:
if ('bias' not in eachVariable.name)and(layerSettings.REGULARIZER_WEIGHTS_DECAY != None):
regularizationLoss = L2_Regularizer(eachVariable)
tf.losses.add_loss(regularizationLoss, loss_collection=tf.GraphKeys.REGULARIZATION_LOSSES)
return outputTensor, stateTensor, statePlaceHolder
2. Unrolls the LSTM
In training the single frame algorithms, the batch data will be the shape: (batch_size, w, h, c). While training the video algorithms, the batch data will be the shape: (batch_size, unrolled_size, w, h, c). Here, the batch_size means how many videos in this batch while the unrolled_size means how many frames per video.By applying the tf.nn.dynamic_rnn(), which takes the input tensor and the LSTM cell as arguments, it will unroll the input in the second dimension and feed it into the LSTM cell.
3. Start training with a few Unroll Size
Several studies (such as Re3 and here) show that one should start with a larger batch_size and a smaller unroll_size while training the network with the LSTM. Otherwise, the network will not converge. Namely, the user should start with a bunch of videos (say 40 videos, for example), but with a few frames (say 2 frames per video, for example). Then double the number of unrolls and halve the batch_size while the network reaches the loss plateaus, as suggested by the Re3. For example, input 20 videos and 4 frames per video while the network reaches the first plateau.Nonetheless, the above situation does not occur in my recent project: Without the use of above method, the network still converges easily. And the use of the above method does not improve the network to converge to the lower minima as well. However, I think it's still advantageous for one to start training with the above method.
4. Which should be fed into the current network: the output or the label of the previous time?
In the deploying time of NLP, the output of the previous frame should also be inputted to the network, as shown in the following figure.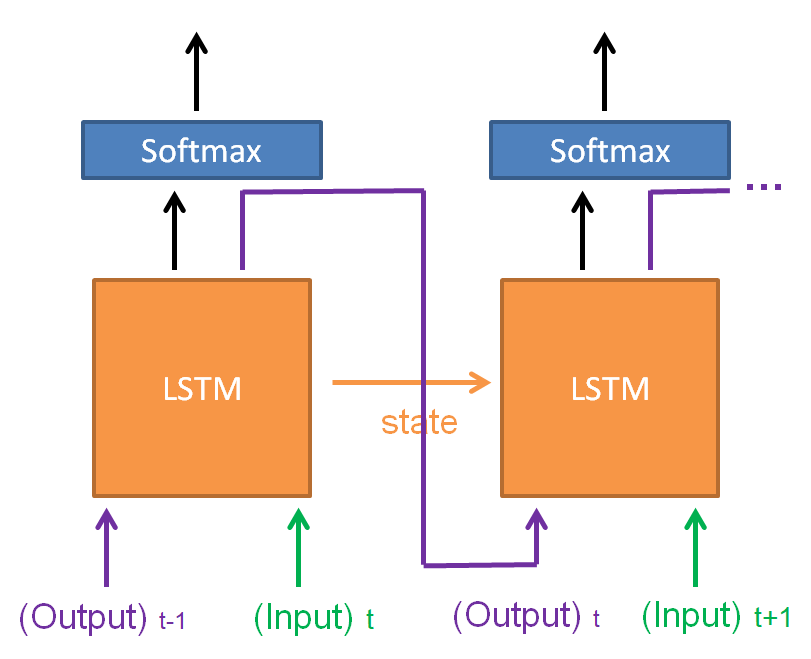
In training, however, the label of the previous frame should be inputted instead, as shown follows.

The Re3 network will track the object in the next frame by input two cropped images: The first cropped image is an image in the previous frame that cropped by the bounding box of the interested object (actually, it is as twice the size as the bounding box). The second cropped image is a sub-image that cropped in the same way as the first cropped image (i.e. the same (x, y, w, h) as the previous crop), but apply on the current frame image. The output of the network is the bounding box of the interested object in the current frame. The current frame is then cropped by such output bounding box and will be used as the previous frame for the next run.
The way to crop the current frame is similar to the mechanism shown in the above figure: During deploying, the crop coordinate of the current frame is determined by the previous output. However, one should use the previous label of bounding box while training and slightly increase the probability to use the previous output after some condition met. In Re3, the probability of using the previous label starts with 0 than plus 0.25 while the user increases the unroll size.
5. The cell state of the LSTM should be maintained in a different way while train and deploy, respectively.
While training the LSTM, the cell state is reset to zeros per video. Suppose that the input batch is of the shape: (b, u, w, h, c) and the LSTM has N neurons, one should create the initial cell state as:
initialCellState = tuple( [np.zeros([b, N])] * 2 ) initialCellState = tf.nn.rnn_cell.LSTMStateTuple(initialCellState[0], initialCellState[1])Note that the initialCellState includes both the hidden state and the output state.
While deploying, the cell state should be maintained and then pass to the feed_dict each frame by the user. Furthermore, the user should get the value of the LSTM states by sess.run() the state tensor of the LSTM. The deploying procedure looks like:
inputFeedDict = { self.net.inputImage : batchData.batchOfImages,
...
self.net.isTraining : False
}
cellStateFeedDict = self.net.GetFeedDictOfLSTM(...)
inputFeedDict.update(cellStateFeedDict)
loss, listOfPreviousCellStates = session.run( [ self._lossOp] + self.net.GetListOfStatesTensorInLSTMs(),
feed_dict = inputFeedDict )
To decouple the train/deploy from the network design, I define the interface of the networks as follows:
class NetworkBase: __metaclass__ = ABCMeta @abstractmethod def Build(self): pass @abstractmethod def GetListOfStatesTensorInLSTMs(self): pass @abstractmethod def GetFeedDictOfLSTM(self, BATCH_SIZE_, listOfPreviousStateValues_=None): passAnd one possible implementation of a network that contains one LSTM is shown as follows (see here for more detail):
class Net(NetworkBase):
def __init__(...):
...
def Build(self):
...
out, self._stateTensorOfLSTM_1, self._statePlaceHolderOfLSTM_1 = LSTM( "LSTM_1",
out,
self._NUMBER_OF_NEURONS_IN_LSTM,
isTraining_=self._isTraining,
dropoutProb_=self._DROPOUT_PROB)
...
def GetListOfStatesTensorInLSTMs(self):
return [self._stateTensorOfLSTM_1]
def GetFeedDictOfLSTM(self, BATCH_SIZE_, listOfPreviousStateValues_=None):
if listOfPreviousStateValues_ == None:
'''
For the first time (or, the first of Unrolls), there's no previous state,
return zeros state.
'''
initialCellState = tuple( [np.zeros([BATCH_SIZE_, self._NUMBER_OF_NEURONS_IN_LSTM])] * 2 )
initialCellState = tf.nn.rnn_cell.LSTMStateTuple(initialCellState[0], initialCellState[1])
return {self._statePlaceHolderOfLSTM_1 : initialCellState }
else:
return { self._statePlaceHolderOfLSTM_1 : listOfPreviousStateValues_[0] }
Therefore, in training, one could just (see here for more detail):
inputFeedDict = { self.net.inputImage : batchData.batchOfImages,
...
self.net.isTraining : True,
}
'''
For Training, do not use previous state. Set the argument:
'listOfPreviousStateValues_'=None to ensure using the zeros
as LSTM state.
'''
cellStateFeedDict = self.net.GetFeedDictOfLSTM(batchData.batchSize, listOfPreviousStateValues_=None)
inputFeedDict.update(cellStateFeedDict)
session_.run( [self._optimzeOp],
feed_dict = inputFeedDict )
While in deploying, one could simply (see here for more detail): inputFeedDict = { self.net.inputImage : batchData.batchOfImages,
...
self.net.isTraining : False,
}
cellStateFeedDict = self.net.GetFeedDictOfLSTM(batchData.batchSize, self._listOfPreviousCellState)
inputFeedDict.update(cellStateFeedDict)
tupleOfOutputs = session.run( [ self._lossOp] + self.net.GetListOfStatesTensorInLSTMs(),
feed_dict = inputFeedDict )
listOfOutputs = list(tupleOfOutputs)
batchLoss = listOfOutputs.pop(0)
self._listOfPreviousCellState = listOfOutputs
6. Gradient Clipping
It's well known that the LSTM suffer from gradient explosion. Therefore, the gradients are often examined and clipped to a certain range. See here for gradient clipping in TensorFlow.In Re3, they state that it is not necessary to clip the gradients if one applies the training strategy that starts with a few unrolls. However, in my recent project, the exploding gradients happened even if I apply such training strategy.
沒有留言:
張貼留言